

JustLend DAO完成首轮JST回购
原文来源:新智元
DeepMind的研究人员发现,LLM有一个天生的缺陷——在推理过程中无法通过自我纠正获得更好的回复,除非数据集中预设了真值标签。马库斯又高兴地转发了这篇论文。

图片来源:由无界AI生成
大语言模型又一项重大缺陷被DeepMind曝光!
LLM无法纠正自己推理中的错误。
「Self-Correction」作为一种让模型修正自己回答的技术,在很多类型的任务中都能明显改进模型的输出质量。
但是最近,谷歌DeepMind和UIUC的研究人员却发现,对于推理任务,LLM的「自我纠正机制」一下子就没用了。

而且LLM不但不能自我纠正推理任务的回答,经常自我纠正之后,回答质量还会明显下降。

马库斯也转发了这篇论文,希望让更多研究人员关注大语言模型的这一缺陷。
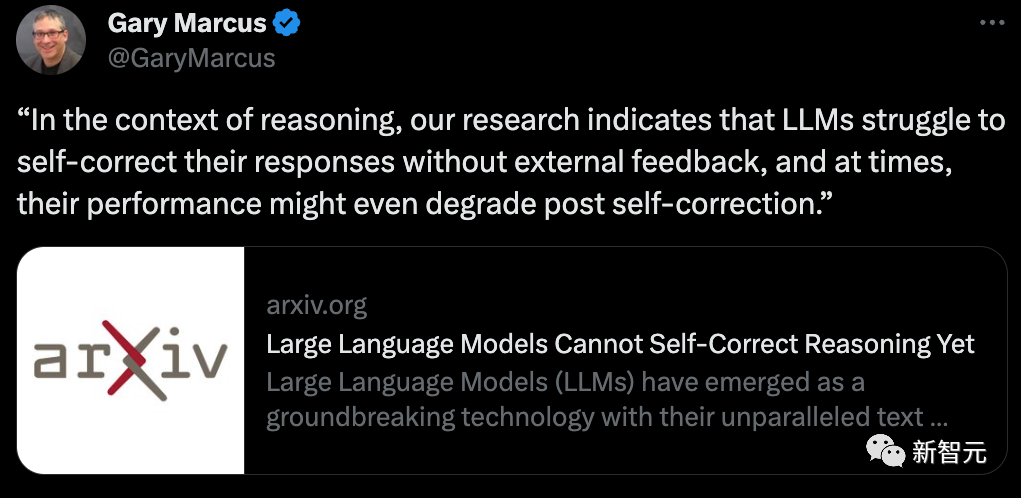
「自我纠正」这一技术是基于一个简单设想——让LLM对自己生成的内容根据一定标准来进行纠正和改进。这个方法在数学问题等任务上能明显提高模型的输出质量。
但是研究人员发现,在推理任务中,自我纠正之后的反馈有时很不错,有时效果却很不理想,甚至性能还会出现下降。
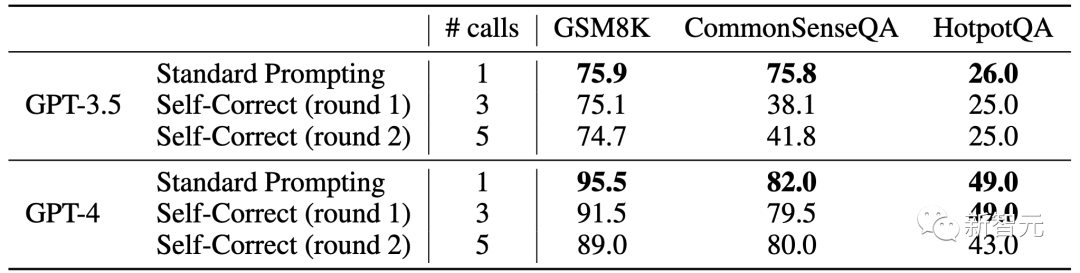
研究人员又研究了那些认为「自我纠正」可以改进推理输出的文献,经过仔细检查发现,「自我纠正」的改进来自于引入了外部的信息来指导模型自我纠正。而当不引入外部信息时,这些改进就会消失。
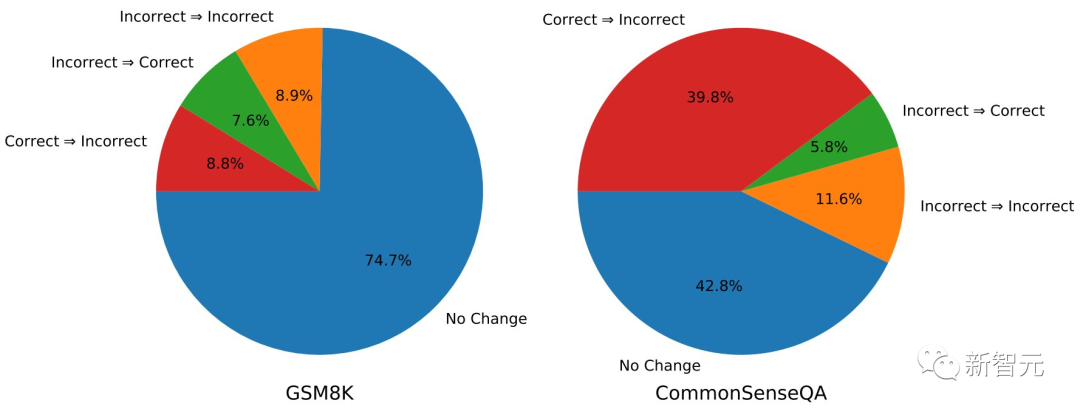
具体来说,当模型能够访问基准数据集中包含的真值标签(ground-truth labels)时,自我纠正就能有效地发挥作用。
这是因为算法可以准确地确定何时停止推理过程,并避免在答案已经正确时更改答案。
研究人员认为,先前的研究中往往会使用真实标签来防止模型将正确答案更改为错误答案。但如何防止这种「对改错」情况的发生,实际上是确保自我纠正成功的关键。
因为当研究人员从自我纠正过程中删除真实标签时,模型的性能就会显著下降。
作为改进LLM在推理任务上自我纠正方法的尝试,研究人员还探究了「多智能体辩论(multi-agent debate)」作为改进推理的手段的潜力。然而,他们的结果表明,在考虑同等数量的响应时,这个方法的效果并不比自我一致性(Self-Consistency)更好。
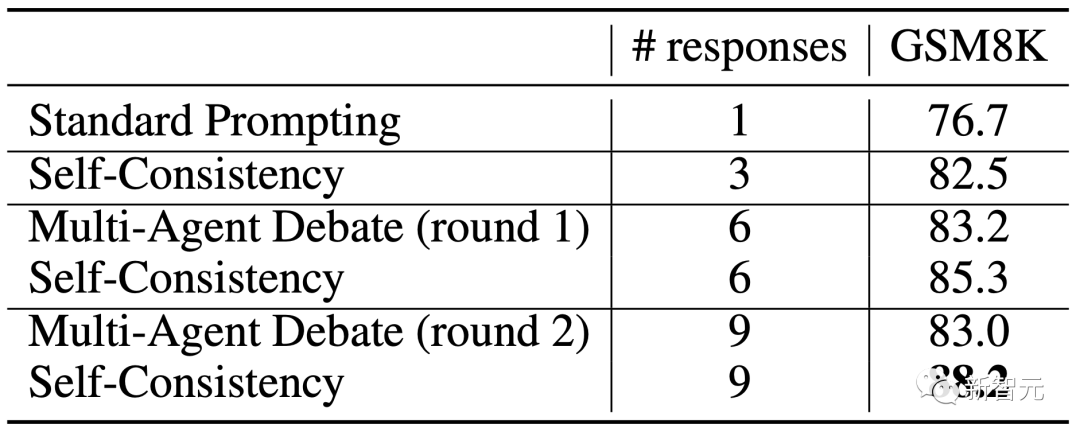
研究人员进一步提出了「事前提示」和「事后提示」的概念。
他们将自我纠正视为事后提示的一种形式,其中纠正的提示是在LLM的回复之后再输入的。
研究人员的分析表明,某些任务中自我纠正带来的增强可能源于精心设计的反馈提示,掩盖了简陋的初始提示。
在这种情况下,将更好的反馈集成到初始指令中或设计更好的初始提示可能会产生更好的结果并降低推理成本。
根据研究人员的研究结果,研究人员深入探讨了LLM自我纠正能力的细微差别,敦促研究社区能以更加严谨的态度来对待对自我纠的研究。
大语言模型可以自我纠正自己的推理吗?
研究人员尝试采用现有的自我纠正方法,采用其设置(使用标签来指导自我纠正过程),以检查其在提高LLM推理任务表现方面的有效性。
提示词
研究人员采用三步提示策略进行自我修正:
1)提示模型进行初始生成(这也是标准提示的结果);
2)提示模型回顾其上一代并产生反馈;
3)通过反馈提示模型再次回答原来的问题。
模型
研究人员的主要测试是在 GPT-3.5-Turbo 上进行的。
研究人员还对2023年8月29日访问的GPT-4进行了测试,旨在测试OpenAI模型最新、最强大的迭代的自我校正能力。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

