

JustLend DAO完成首轮JST回购
原文来源:机器之心

图片来源:由无界 AI生成
本文是 Meta 官网推出的 Llama2 使用教学博客,简单 5 步教会你如何使用 Llama2。
在这篇博客中,Meta 探讨了使用 Llama 2 的五个步骤,以便使用者在自己的项目中充分利用 Llama 2 的优势。同时详细介绍 Llama 2 的关键概念、设置方法、可用资源,并提供一步步设置和运行 Llama 2 的流程。
Meta 开源的 Llama 2 包括模型权重和初始代码,参数范围从 7B 到 70B。Llama 2 的训练数据比 Llama 多了 40%,上下文长度也多一倍,并且 Llama 2 在公开的在线数据源上进行了预训练。

Llama2 参数说明图
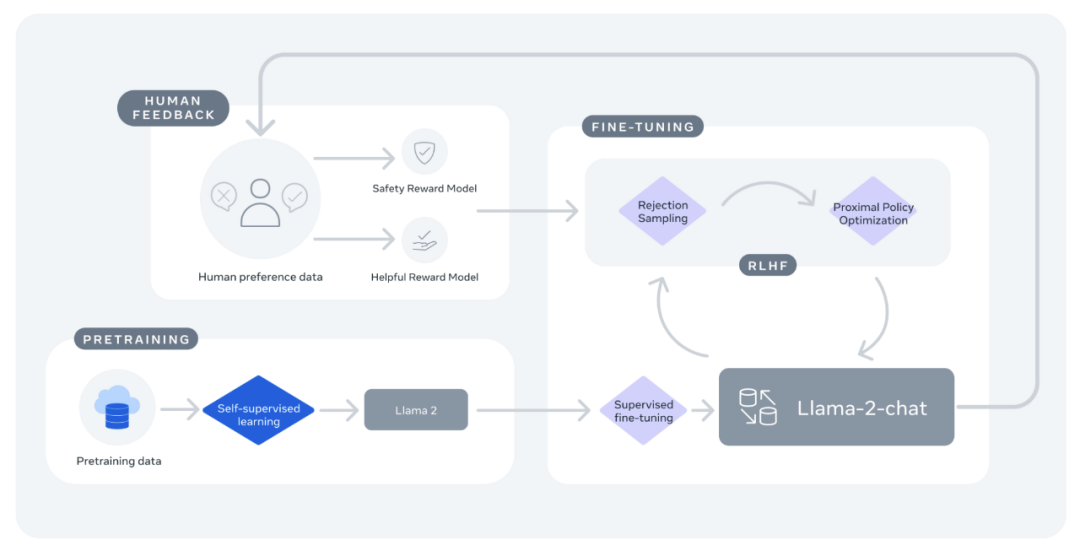
Llama2 流程说明图
在推理、编码、熟练程度和知识测试等多项外部基准测试中,Llama 2 的表现均优于其他开放式语言模型。Llama 2 可免费用于研究和商业用途。
下一节中将介绍使用 Llama 2 的 5 个步骤。在本地设置 Llama 2 有多种方法,本文讨论其中一种方法,它能让你轻松设置并快速开始使用 Llama。
开始使用 Llama2
步骤 1:前置条件和依赖项
本文将使用 Python 编写脚本来设置并运行 pipeline 任务,并使用 Hugging Face 提供的 Transformer 模型和加速库。
pip install transformers
pip install accelerate步骤 2:下载模型权重
本文使用的模型可在 Meta 的 Llama 2 Github 仓库中找到。通过此 Github 仓库下载模型需要完成两步:
git clone https://github.com/facebookresearch/llama启动 download.sh 脚本(sh download.sh)。出现提示时,输入在电子邮件中收到的预指定 URL。
运行 ln -h ./tokenizer.model ./llama-2-7b-chat/tokenizer.model,创建在下一步的转换时需要使用的 tokenizer 的链接。
转换模型权重,以便与 Hugging Face 一起运行:
TRANSFORM=`python -c"import transformers;print ('/'.join (transformers.__file__.split ('/')[:-1])+'/models/llama/convert_llama_weights_to_hf.py')"`
pip install protobuf && python $TRANSFORM --input_dir ./llama-2-7b-chat --model_size 7B --output_dir ./llama-2-7b-chat-hfMeta 在 Hugging Face 上提供了已转换的 Llama 2 权重。要使用 Hugging Face 上的下载,必须按照上述步骤申请下载,并确保使用的电子邮件地址与 Hugging Face 账户相同。
步骤 3:编写 python 脚本
import torch
import transformers
from transformers import LlamaForCausalLM, LlamaTokenizer加载模型
接下来,用下载好并转换完成的权重(本例中存储在 ./llama-2-7b-chat-hf 中)加载 Llama 模型。
model_dir = "./llama-2-7b-chat-hf"
model = LlamaForCausalLM.from_pretrained (model_dir)定义并实例化分词器和流水线任务
在最终使用之前确保为模型准备好输入,这可以通过加载与模型相关的 tokenizer 来实现。在脚本中添加以下内容,以便从同一模型目录初始化 tokenizer:
tokenizer = LlamaTokenizer.from_pretrained (model_dir)免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

